
After an event like Worlds, there is always ample opportunity to start hitting the lists and trying to mine some useful data out of it. First, I’d like to congratulate Rookie of the Year Aaron Nicastri for 6-0ing Standard with his version of Boat Brew, a deck that I’ve spent some amount of time championing. It’s a great deck, and if Standard were a particularly relevant format in tournaments right now, I’d probably be playing it myself. Second, I’d like to congratulate Madison’s Sam Black and the rest of Team USA for winning it for us. It looked touch and go there, for a while, but I’m proud that you pulled it off. Finally, I’d love to congratulate old-school pro Jamie Parke for his fantastic finish. I was heavily rooting for you, buddy.
While I could go on and on, congratulating people ad nauseam, I have too much to cover, so I’d like to get right down to it. By the time it was getting close to my deadline, there were already so many articles touching on the Constructed side of things, I thought I would turn the corner around, and look at Shards of Alara Draft. There really isn’t much time left in the PTQ season. Two weekends. But that’s enough time to potential squeak in that final Q…
When approaching draft, the best, best, best thing that you can ever do is draft it. Draft it often. And draft it with as many quality people as you can. Drafts are particularly dynamic. If you’re constantly drafting with a weak pool of people, you will rise up a little bit, perhaps, but more often, you’ll just stay at about the same level. In many ways, it is similar to raising your DCI rating. If you only draft at FNM, unless you have a particularly skilled pool of players, it doesn’t make for a great way to raise your rating.
Drafting on MTGO is a big help. It has some major limitations, though. The most important one is that you can’t actually see the lists that won (and those that lost). When you’re drafting in person, you are afforded that fantastic opportunity to see what everyone else is doing. That is the dynamic that will help you the most. At its best, you’ll have the kind of situation that Madison used to have back in its first Golden Age, two tables of six- or eight-man drafts going on at once, with every participant having at least six or more Pro Tours under their belt, and many having some major event Top 8s, if not championships. While you don’t need this degree of talent, the more people you have, with different concept of how to solve the format, the more likely you are to discover the best way(s) to draft in that format.
In many ways, this is the kind of ideal situation I describe in last week’s magnum opus, “Deck Discovery and Collective Intelligence in Magic”. You are operating with a mini Hive Mind, and discovering things through interaction and discourse that none of you could have figured out on your own.
The problem is, of course, that access to this kind of group is exceedingly rare.
Currently, for example, in Madison, we’re experiencing a kind of new Renaissance, but we’re still nowhere near where we’d been in the past. Madison’s well(ish)-known figures, these days, are probably Sam Black, Gaudenis Vidugiris, Brian Kowal, and a few others. There is still a ton of talent here, much of it doing quite well recently at GPs, like Indy Top 8 player Ben Rasmussen, and the rest of the Madison GP crew. Many other players who used to be here have retired or moved on to other pastures. I can’t remember the last time Bob Maher played Magic with the rest of us mere mortals (perhaps at Kowal’s recent wedding reception?), but whatever the case may be, even if Madison is once again deepening its talent pool, it is by no means the crazily top-heavy talent pool it once had. Like many communities, it has a lot of excellent players, but not nearly the ridiculous depth that makes one gasp.
And so, like most groups, we can get a great deal of play out of accessing Crowd Wisdom, that crazy thing that happens when we look at the aggregate successful decks. We can never know how hard a PTQ was unless we were there (or we know a lot of the names in the Top 8). At best we can guess. Even so, though, we can discover something meaningful in trends for decks from looking at the successful lists at various PTQs, even if we can’t gauge how hard the journey is. All we need is enough data.
To access the Hive Mind, then, we need to pay attention to this raw data. Players all over the place are doing the work for us, every week. If you want to keep up with the Joneses, you really, really, really should be doing things like checking out all the decklists you can. I keep the hyperlink to Wizards of the Coast and StarCityGames current decklist handy in my bookmarks for easy reference — this is especially important for the Wizards site, seeing as the links can oh-so-easily become hard to find, like animal tracks covered up by rain. *Sigh*.
By data-mining the current qualifier season, there really is an incredible wealth of information, if you want to go through all of the data. I’ve separated the PTQ data into three categories, small (up to 90 players), large (91 to 180), and huge (181 or more). While it isn’t strictly true, generally speaking, larger PTQs hold a greater talent pool, simply on odds. As such, there will generally be some degree of correlation between number of players and the skill of the players in the Top 8; it isn’t perfect, but it is a solid measure.
Here are those PTQs:
Fifteen small (0-90)
October 11: Bryant: Eric Jones (Attendance: 80)
October 11: Roanoke: Kenny Mayer (Attendance: 82)
October 11: Standish: Dave Nolan (Attendance: 79)
October 11: Wichita: Jonathan Klimek (Attendance: 44)
October 18: San Antonio: William Lowry (Attendance: 71)
October 25: Indianapolis: Ryan Bushard (Attendance: 81)
October 25: Louisville: Charles Colglazier (Attendance: 63)
November 1: Dallas: Casey Stewart (Attendance: 83)
November 15: Des Moines: Pat McGregor (Attendance: 82)
November 15: Springfield: Charles Gabbert (Attendance: 66)
November 22: Burlington: Bryan Mabie (Attendance: 73)
November 22: Oklahoma City: Andrew Young Vargas (Attendance: 57)
November 29: Albuquerque: Andrew Hanson (Attendance: 49)
November 29: Winnipeg: Janet Bishop (Attendance: 43)
December 6: Phoenix: Joseph Lee (Attendance: 78)
Nineteen large (91-180)
October 4: Columbus: Ari Lax (Attendance: 125)
October 11: Fort Lauderdale: Chris Fennell (Attendance: 92)
October 11: Madison: Jens Erickson (Attendance: 94)
October 11: Sacramento: Sam Sherman (Attendance: 153)
October 11: Vancouver: Tyler Sage (Attendance: 134)
October 18: Atlanta: Matt DeLoach (Attendance: 110)
October 18: Milford: Yoni Skolnik (Attendance: 154)
October 18: Montreal: Zack Spence (Attendance: 94)
October 26: Richmond: Nathan Zimmerman (Attendance: 130)
October 26: Rochester: Josh Ravitz (Attendance: 165)
November 1: Pittsburgh: Blaine Campbell (Attendance: 136)
November 2: Los Angeles: Kevan Emami (Attendance: 125)
November 15: San Diego: Basil Nabi (Attendance: 99)
November 22: Kitchener: Nathan Braymore (Attendance: 91)
November 22: Boston: Christopher Manning (Attendance: 169)
November 22: Chicago: Max Gollop (Attendance: 139)
November 22: Las Vegas: Hunter Coale (Attendance: 103)
November 29: Minneapolis: Gaudenis Vidugiris (Attendance: 129)
December 6: Portland: Nick Slind (Attendance: 150)
Six huge (181 plus)
October 11: Edison: Peter Yong (Attendance: 230)
October 18: Seattle: Charles Wong (Attendance: 198)
October 19: Kansas City: Dustin Marquis (Attendance: 302)
October 25: San Jose: Casius Weathersby (Attendance: 188)
November 1: Berlin: Kashiwa Tatsuya (Attendance: 343)
November 22: Philadelphia: Max Tietze (Attendance: 211)
Let’s take a glance at the raw data from the small PTQs first:
The “Small” Data
I’ll use this first table to explain how it is I’m working with the data.
As you can see, in these fifteen PTQs, thirteen discreet archetypes were drafted. In making decisions about which archetypes to place a deck into, Shards of Alara is interesting, in that the color-fixing can oftentimes make distinctions hard. For an Esper deck that is splashing, say, an Empyrial Archangel, I chose to call that “Esper.” If, on the other hand, it splashed a great deal more Green, I would call it “Esper/Bant.” This is not exactly science, obviously. I just tried to exercise my best judgment.
I think the next thing that is worthy of comment is the “average” place of every deck. To my mind, as the PTQs are reported, there is no difference between a 3rd place or 4th place finish. Similarly, there is no difference for 5th through 8th. As a result, I place an equivalent weight to those finishes, summing them up as 3.5th place to 6.5th place, respectively, the average of the range of placements in those finishes.
How to evaluate the effective weight of these finishes is largely arbitrary. Aside from the average, I have provided two other weighted finishes. The first, labeled “Points” assigns a value of 6 points for a 1st place finish, 3 points for 2nd, 1 point for 3rd/4th, and 0 points for 5th-8th. This weighting does not reward an archetype for a player playing it, but does reward it for winning with it. The second, labeled “Points (penalty) penalizes that archetype for failing to get a win (5th-8th). The weights are 8 points for a 1st place finish, 4 points for 2nd, 1 point for 3rd/4th, and negative 1 for 5th-8th. I actually believe that this second model is perhaps more useful, but, again, these numbers really are arbitrary. They represent my best guesses for the value of match wins. I prefer the penalized version because it places some negative to an archetype being popular (which makes it harder to draft) as well as noting the lack of the unsuccessful.
With that out of the way, let’s look at the data:
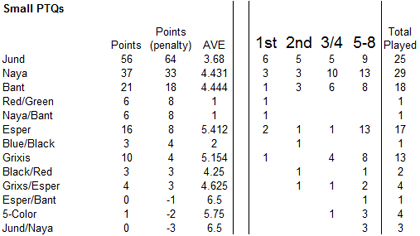
First of all, in small PTQs, Jund is clearly the most successful archetype. A shocking six out of fifteen players drafted it, finishing, on average 3rd/4th. It was among the more popular archetypes, to be fair, but hardly the most popular. Naya, the most popular archetype, was also the second-highest scorer by my two weighted Points. Even unweighted, with simple averages, it is third most performing, following Jund and then Black/Red.
Do note that for any Top 8, under these weights, 4.5 would be the “average” for any archetype. This means that of the archetypes seeing play by more than one player, only Jund, Naya, Bant, and Black/Red performed above average. It’s very worth nothing that Black/Red was only played by two players out of the entire 120 available.
Jund and Black/Red share a lot of common possibilities. A Black/Red deck, after all, is just a Grixis or Jund deck without one of the colors. This archetype typically is going to be very aggressive, and most Jund decks are similarly aggressive.
Compare this to Grixis, which (along with Esper) was a very poor performer. While popular, Grixis and Esper were decks that generally would place you as a first-round loser. Esper is particularly bad, with over three quarters of Esper players failing to go into the semis.
Obviously, this does not mean that you should simply draft Jund. If everyone choose to draft Jund, it will be the Blue/White based player that will likely run away with the draft. Draft is a format that rewards a player’s ability to find what is underdrafted. It becomes worth noting, however, that even though Jund is not underdrafted, it is finding the W bracket. It does mean that if you’re struggling between a choice of archetypes early in the draft, you should remember that Jund is more of a winner than, say, Grixis. Still, though, as one draft shows, when three of the eight players drafted Jund (the ostensible “best” deck), they all failed to get a win.
Still, though, this is only a snapshot of those events that are likely to be statistically less skilled. Let’s take a step up to the next level.
The “Large” Data
The data from larger events is also illustrative.
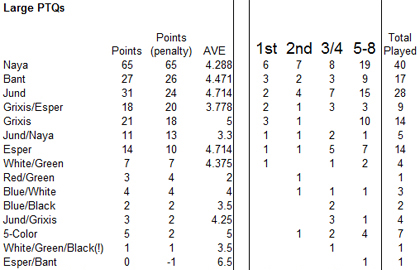
Naya is clearly deeply popular in bigger events, but actually has a similar win rate to Bant. Jund has dropped off in popularity, but still remains one of the big decks. The huge surprise, though, has to be the emergence of Grixis/Esper decks, which, while not deeply popular, have a very exciting win percentage. Further, Jund/Naya and Jund/Grixis become worth noting.
If we refine our data, somewhat, to ignore “outlier” cases, of only one or two people drafting an archetype, and to pool all of the four-plus color decks together, we can get an even better picture, especially if we focus more on the pure “average” finish:
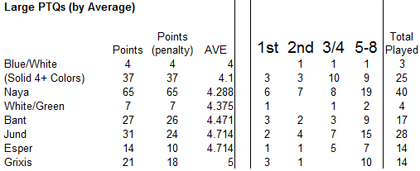
Here we have a kind of shocking revelation: solidly 4+ color decks are actually outperforming, in some measures, clear Shards. This is exciting news to me, because I’ve deeply been enjoying drafting Five-Color as an archetype — though it is worth noting that this archetype appears to be the least performing of the multi-Shard archetypes. This is not a reference to, say, a Bant deck splashing a Red spell, but rather a deck that is fully committed to four or more colors. This news is definitely worth thinking about. Its poor performance at smaller PTQs may correlate to a higher degree of skill needed to be able to run the archetype.
Another thing worth noting is that there is a general leveling out of the advantages that can be found in any particular Shard. My gut says that this is probably because at higher-skill tables, people are more likely to pick up on the fact that a Shard is under-drafted. This means that a player can’t simply run away with an archetype, because if the cards are there, the better player-base is likely to pick up on this. In a way, this homogenizes results, but that isn’t surprising.
White/Green shows up as a viable archetype, though Black/Red completely disappears. Esper and Grixis, as before, continue to underperform. Again, it may be worth noting that it is deeply possible that those archetypes might tend towards weaker, as a general rule.
The “Huge” Data
With only six PTQs here, it stands to reason that it would be useful to toss in the Grand Prix results as well. Once we join Kansas City, Paris, Atlanta, Okayama, Taipei, and Auckland, to the PTQ results, we get the following:
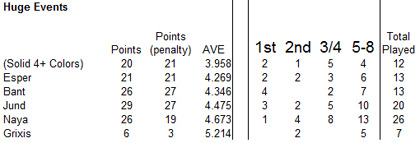
This uses a similar compilation data that was used for the “large average,” above. There are some interesting things in this data as well. The outliers, decks like W/G, played by almost no one, didn’t perform. Archetypes remain at a similar level of performance, but the average performance of an archetype is almost completely related to how many people played it!
That is to say, at the best levels of performance, the underdrafted archetype rose to the top. This is unsurprising, since players at this level are likely to pick up on the fact that someone is not drafting an archetype. The sole exception is Grixis. Grixis was almost completely not drafted, but even those that chose to draft it were largely destroyed. The negative performance of Grixis flows through all of the demographics. This leads me to the conclusion that Grixis is perhaps only a good choice if no one is paying any attention to that Shard, or if your particular card quality is through the roof.
Bant showed an explosion in successes. While a part of this might be because it was only over 12 events, fully a third of them were won by the Shard. Is it that drafting Bant successfully (a Shard only moderately performing in smaller events) is simply just very hard?
Wrap-up
Statistical analysis of any format won’t give you the end-all be-all definitive idea of what archetype is the best in general, let alone in any specific draft, but it can give you reliable ideas of what is good or not good. In a weaker event, going for pure power of an archetype is more reasonable. Jund has some of the most powerful cards, and if people aren’t picking up on that, you can run with it to great success. Bant and multi-Shard decks are reasonable, but appear to have a high skill-threshold to be successful with. In stronger events, seeking out the underdrafted Shard is key in this format (the Ervin Tormos approach). Even if underdrafted, Grixis tends to be weak. Esper also appears to be weak in the hands of all but the most skilled.
You can access this data without even drafting once. While clearly, practice makes perfect, the raw data that is available out there can greatly arm you in the battle you’ll engage in should you make Top 8 of a PTQ in the next two weeks. All of this is just a way to actively apply the ideas that I brought up last week in “Deck Discovery and Collective Intelligence in Magic”. It is 6,000+ words, but I highly recommend it.
Good luck, this weekend, any of you PTQers out there. I’ll be trying to jam as many drafts as I can before the PTQ in Chicago next week. Wish me luck!